서문
안녕하세요. Flative 의 최현빈입니다.
저는 파이썬을 시작한지 얼마 되지 않은 개발자입니다. 그렇기에 혼자 프로젝트를 진행을 한다면 무엇이 좋을까 생각하다 결정하게 된게 크롤러 입니다.
뮤지컬에도 관심이 많았고, 나 자신이 필요로 하는 뮤지컬 정보만 보기 좋게 편하게 만들고자는 목적으로 만들게 되었습니다. 그리고 간단하게 크롤러 만드는 방법과 기술을 공유하고자 하여 이 글을 작성하게 되었습니다.
사용 라이브러리
라이브러리 목록 :
- BeautifulSoup : HTML 코드를 개발자가 보기 좋게 파싱하는 라이브러리입니다.
- Requests : 파이썬으로 HTTP 요청을 보내고 받을 수 있는 라이브러리 입니다 .
간단하게 설명하자면 Requests를 통해 웹페이지에 요청을 보내어 BeautifulSoup를 통해 HTML 코드를 파싱을 하여 필요 정보를 추출 해내는 것입니다.
BeautifulSoup 사용하여 크롤러 만들기
아래의 코드을 통해 requests를 통해 요청을 주고 받은 후 돌려 받은 데이터를 BeautifulSoup와 lxml를 이용하여 파싱을 진행하였습니다. BeautifulSoup에서 기본으로 제공을 해주는 html.parser 란 것이 있는데 그 보다 lxml 파서가 더 좋다는 이야기를 들어 해당 파서를 사용하였습니다. 관련된 내용은 추후 작성 할 수 있다면 포스팅을 하도록 하겠습니다.
musical_url = 'http://ticket.interpark.com/Ticket/Goods/GoodsInfo.asp?GroupCode=16009835'
musical_source_code = requests.get(musical_url)
musical_plain_text = musical_source_code.text
musical_soup = BeautifulSoup(musical_plain_text, 'lxml')
(lxml 파서의 경우 다른 라이브러리들과 마찬가지로 별도로 설치를 진행하셔야 사용 할 수 있습니다. 저자는 간단하게 pip install lxml 을 통해 설치하였습니다.)
위의 방식으로 파싱을 진행 한 후에는 저자의 경우 간단하게 BeautifulSoup의 두가지의 기능만을 사용하였습니다.
musical_title = musical_soup.find(id="IDGoodsName")
# find로 찾을 때 class를 이용할 경우
musical_etc_tag = musical_soup.find('dd', attrs={'class': 'etc'})
첫번째 기능은 find 라는 기능입니다. 주로 하나의 것 아래와 처럼 어떠한 tag에 id로 정확하게 쓰인 것을 찾을 때 사용하였습니다. 물론 find 도 class 를 통해 태그의 클래스 단위로 쓰인 것을 찾을 수 있으나 클래스 단위로 찾을 것이라면 두번째로 소개할 기능을 사용하는게 조금 더 편하다고 생각을 합니다.
musical_member_list = musical_soup.select('li.members > div > a')
두번째 기능은 select 라는 기능입니다. 저자는 주로 이 기능을 여러가지의 내용을 가져올 때 사용하였습니다. 위의 처럼 태그의 태그의 태그로 가서 데이터를 찾아 올 수 있고 해당 태그의 class 를 사용하여 좀더 가져올 데이터들의 범위를 좁힐 수 있습니다.
이 외에도 정말 무식하게는 코드를 뜯어내어 해당 값을 직접 추출 할 수도 있지만 굉장히 노가다가 심한 작업이였기에 최대한 위의 방법들을 사용하여 데이터를 추출하는게 효율적이라고 생각합니다.
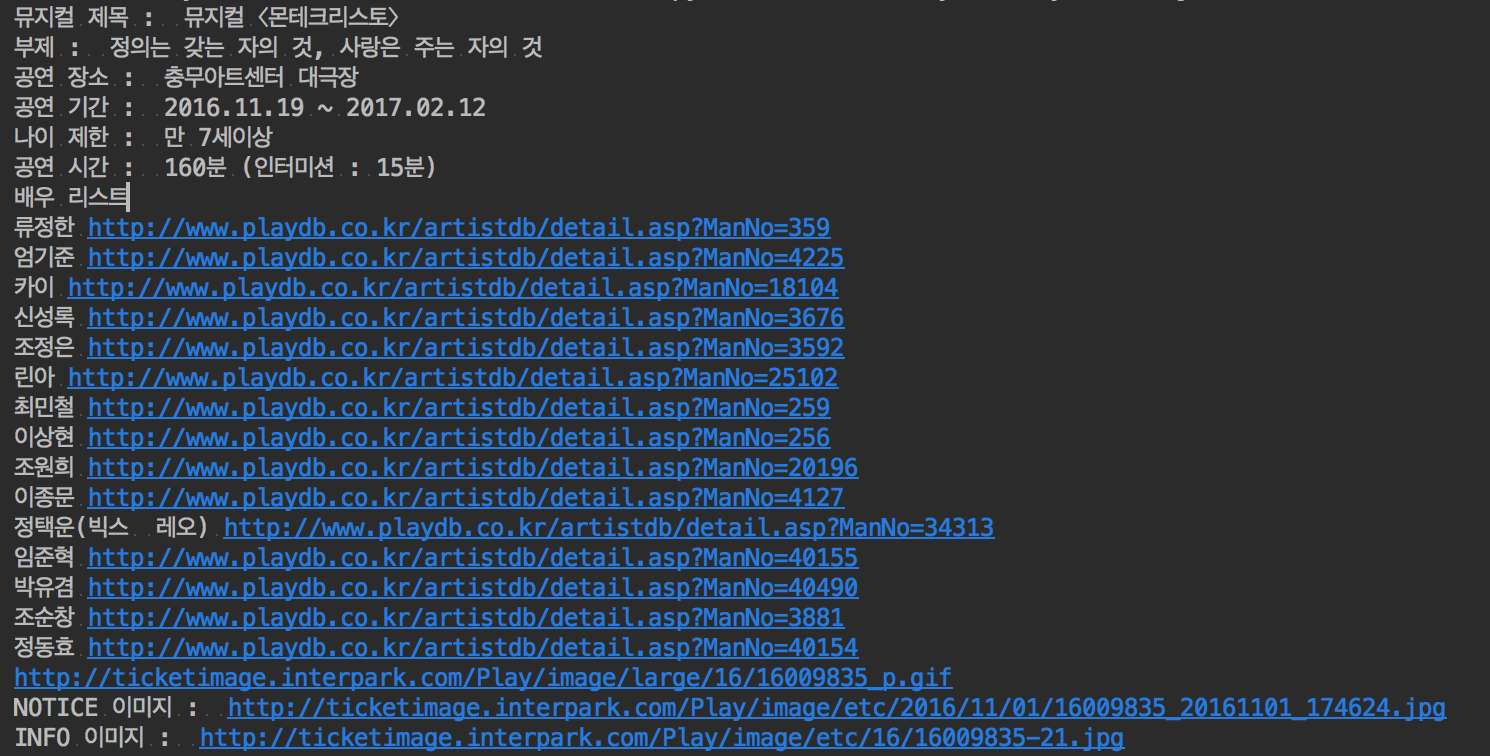
뮤지컬 크롤러 결과 화면
정말 별것도 아닌데 출력되는 결과물 보고 뿌듯 했습니다.
작업을 하며 느낀점
-
가장 크게는 크롤러를 만드는 작업이 정말 무식하게는 노가다적인 일로 만들 수 있지만 크롤링할 페이지가 같은 구조의 연속이 된다면 여러 경우를 자세하게 분석하여 작업한다면 정말 효율적으로 데이터들을 가져올 수 있을거라고 생각합니다.
-
현재에는 많은 페이지들에서 바로 모든 페이지 정보를 가져오는게 아니고 요청 후 비동기 방식으로 이미지 파일이라던가, 기타 다른 정보들을 요청하여 가져오는 경우가 있어 그 부분을 생각하고 웹페이지를 분석하는 능력을 키워야 겠다는 생각을 하게 되었습니다.
-
이제 필요 데이터 크롤링을 해오지만 아직 DB(DataBase)를 붙이지도 못했고, 크론탭을 통해 반복작업을 시키는 작업만 진행하면 그래도 내가 원했던 크롤러가 완성되니 그래도 기쁜 생각이 듭니다.
-
생각보다 예외 상황(데이터가 들죽 날죽)들이 많아서 테스트를 정말 많이 했는데 인터파크에서 차단 때리는거 아닌가 심히 걱정도 했지만 다행히 무사했습니다. 나중에 실제로 돌릴 때 차단 당할까 걱정입니다.
(Adviser : Flative team 이재연 님, Flative team 김수홍 님)